
Dynamic Table Profile

As a developer at Health Catalyst, I had the opportunity to work with metadata stored in an analytics data warehouse, where the platform kept track of vital information about the data as users created their own data marts. One of my projects was to create simple yet effective data profiles that allowed users to gain insights into their data at a glance.
One powerful way to gain deeper insights into data is through table profiling. By analyzing every column in a table, you can quickly discover key information such as the presence of null values or the number of unique values. To achieve this, I explored a dynamic solution and wrote a suite of SQL stored procedures that could automatically profile a table on command. This allowed me to gain a more thorough understanding of data, beyond just the simple profile counts.
The Solution
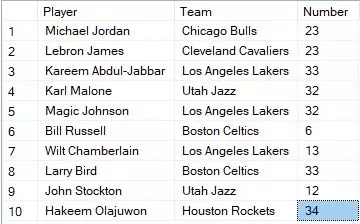
Let's begin by generating sample data to demonstrate how the profiling scripts work. For this purpose, we will create a list of NBA players using a Table Value Constructor statement. The table will consist of columns for player name, team, and number. You can name the table as per your preference. The SQL code to create the table is as follows:
IF OBJECT_ID(N'[dbo].[Players]', N'U') IS NOT NULL
DROP TABLE [dbo].[Players];
SELECT
tbl.[Player],
tbl.[Team],
tbl.[Number]
INTO [dbo].[Players] -- choose what you want to name this table
FROM (
VALUES
('Michael Jordan', 'Chicago Bulls', 23),
('Lebron James', 'Cleveland Cavaliers', 23),
('Kareem Abdul-Jabbar', 'Los Angeles Lakers', 33),
('Karl Malone', 'Utah Jazz', 32),
('Magic Johnson', 'Los Angeles Lakers', 32),
('Bill Russell', 'Boston Celtics', 6),
('Wilt Chamberlain', 'Los Angeles Lakers', 13),
('Larry Bird', 'Boston Celtics', 33),
('John Stockton', 'Utah Jazz', 12),
('Hakeem Olajuwon', 'Houston Rockets', 34)
) AS tbl ([Player],[Team],[Number]);
Let's use SQL Server's system columns to create a table variable containing metadata for our entity's fields. This variable will be used to iterate over the columns of our entity.
Replace the values for @DatabaseNM, @SchemaNM, and @TableNM with your
desired values. Then, execute the following SQL code:
DECLARE @DatabaseNM NVARCHAR(255) = 'master' -- replace
DECLARE @SchemaNM NVARCHAR(255) = 'dbo' -- replace
DECLARE @TableNM NVARCHAR(255) = 'Players' -- replace
DECLARE @SQL NVARCHAR(MAX) = '';
DECLARE @EntityColumnsWithId TABLE (
ID INT PRIMARY KEY,
ColumnNM VARCHAR(255)
)
SET @SQL = '
SELECT
[ORDINAL_POSITION] AS [ID],
[COLUMN_NAME] AS [ColumnNM]
FROM ['+@DatabaseNM+'].[INFORMATION_SCHEMA].[COLUMNS] AS c
WHERE c.[TABLE_SCHEMA]='''+@SchemaNM+'''
AND c.[TABLE_NAME] = '''+@TableNM+'''
'
INSERT INTO @EntityColumnsWithId
EXEC(@SQL);
Next, we'll create a SQL query to pivot all the columns in our table vertically
using a simple case statement. This query will be generated dynamically using
the table variable we created earlier. The resulting table, called
Profile_Pivot, will contain three columns: ColumnID, ColumnNM, and
ValueTXT, where ColumnID is the ordinal position of the column, ColumnNM
is the name of the column, and ValueTXT is the value of the cell in the
corresponding row and column. Here's the SQL code:
DECLARE @NumIDs INT = (SELECT COUNT(*) FROM @EntityColumnsWithId)
DECLARE @ID INT = 1;
DECLARE @SQLWhenClause NVARCHAR(MAX) = '';
WHILE (@ID <= @NumIDs)
BEGIN
DECLARE @ColumnNM VARCHAR(255);
SELECT @ColumnNM = ColumnNM
FROM @EntityColumnsWithId
WHERE ID = @ID
SET @SQLWhenClause = @SQLWhenClause +
CHAR(10) + REPLICATE(' ', 10) +
'WHEN '''+@ColumnNM+''' THEN CAST(tbl.['+@ColumnNM+'] AS SQL_VARIANT) '
SET @ID = @ID + 1
END
IF OBJECT_ID(N'[dbo].[Profile_Pivot]', N'U') IS NOT NULL
DROP TABLE [dbo].[Profile_Pivot];
DECLARE @SQLCaseStatement NVARCHAR(MAX) = '';
SET @SQLCaseStatement = '
SELECT
f.[ColumnID],
f.[ColumnNM],
CASE f.[ColumnNM] '+@SQLWhenClause+'
END AS ValueTXT
INTO [dbo].[Profile_Pivot]
FROM ['+@DatabaseNM+'].['+@SchemaNM+'].['+@TableNM+'] AS tbl
WITH (NOLOCK) CROSS JOIN (
SELECT
[ORDINAL_POSITION] AS [ColumnID],
[COLUMN_NAME] AS [ColumnNM]
FROM ['+@DatabaseNM+'].[INFORMATION_SCHEMA].[COLUMNS] AS c
WHERE c.[TABLE_SCHEMA]='''+@SchemaNM+'''
AND c.[TABLE_NAME] = '''+@TableNM+'''
) AS f'
EXEC(@SQLCaseStatement);
To get an idea of what the generated SQL case statement looks like for this example, you can refer to the following code snippet and screenshot. I have also included the script and the results obtained after executing it.
SELECT
f.[ColumnID],
f.[ColumnNM],
CASE f.[ColumnNM]
WHEN 'Player' THEN CAST(tbl.[Player] AS SQL_VARIANT)
WHEN 'Team' THEN CAST(tbl.[Team] AS SQL_VARIANT)
WHEN 'Number' THEN CAST(tbl.[Number] AS SQL_VARIANT)
END AS ValueTXT
INTO [dbo].[Profile_Pivot]
FROM [master].[dbo].[Players] AS tbl
WITH (NOLOCK) CROSS JOIN (
SELECT
[ORDINAL_POSITION] AS [ColumnID],
[COLUMN_NAME] AS [ColumnNM]
FROM [master].[INFORMATION_SCHEMA].[COLUMNS] AS c
WHERE c.[TABLE_SCHEMA]='dbo'
AND c.[TABLE_NAME] = 'Players'
) AS f

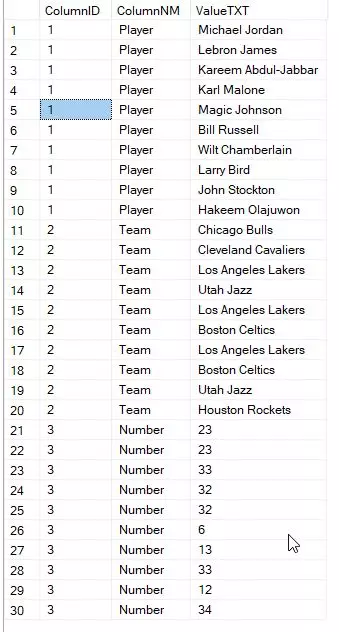
The final SQL query that performs the calculations against the pivoted profile table and combines all the data into one table is as follows:
IF OBJECT_ID(N'[dbo].[Profile_Counts]', N'U') IS NOT NULL
DROP TABLE [dbo].[Profile_Counts];
IF OBJECT_ID(N'[dbo].[Profile_Unique]', N'U') IS NOT NULL
DROP TABLE [dbo].[Profile_Unique];
IF OBJECT_ID(N'[dbo].[Profile_Full]', N'U') IS NOT NULL
DROP TABLE [dbo].[Profile_Full];
-- Get the row, null, and distinct counts
SELECT
pv.[ColumnID],
pv.[ColumnNM],
COUNT(pv.[ValueTXT]) AS [RowCNT],
SUM(CASE
WHEN pv.[ValueTXT] IS NULL THEN 1
ELSE 0
END) AS [NullCNT],
COUNT(DISTINCT pv.[ValueTXT]) AS [DistinctCNT]
INTO [dbo].[Profile_Counts]
FROM [dbo].[Profile_Pivot] AS pv
GROUP BY pv.[ColumnID],pv.[ColumnNM];
-- Get a count of uniqueness
SELECT
uque.[ColumnID],
uque.[ColumnNM],
COUNT(*) AS [UniqueValueCNT]
INTO [dbo].[Profile_Unique]
FROM (
SELECT
[ColumnID],
[ColumnNM],
[ValueTXT]
FROM [dbo].[Profile_Pivot]
WHERE [ValueTXT] IS NOT NULL
GROUP BY [ColumnID],[ColumnNM],[ValueTXT]
HAVING COUNT(*) = 1
) AS uque
GROUP BY uque.[ColumnID],uque.[ColumnNM];
-- Combine all this profile data into one nice table
SELECT
a.[ColumnID],
a.[ColumnNM],
a.[RowCNT],
a.[NullCNT],
a.[DistinctCNT],
ISNULL(b.[UniqueValueCNT],0) AS [UniqueValueCNT]
INTO [dbo].[Profile_Full]
FROM [dbo].[Profile_Counts] AS a
LEFT JOIN [dbo].[Profile_Unique] AS b
ON b.[ColumnID] = a.[ColumnID]
AND b.[ColumnNM] = a.[ColumnNM];
SELECT * FROM [dbo].[Profile_Full] ORDER BY 1;

Overall, by implementing these SQL queries, we were able to create data profiles that provided Health Catalyst users with important insights into their data at a glance. These profiles included useful information such as row counts, null counts, distinct value counts, and counts of unique values. By pivoting the data and aggregating the results, we were able to easily summarize important information about the data. This project allowed me to utilize my SQL skills and work with metadata in an analytics data warehouse. The resulting data profiles provided users with valuable insights into their data, fulfilling the project's goal of creating simple yet effective data profiles.
